The Economist Who Named the Problem#
In 1975, Charles Goodhart — then a chief adviser to the Bank of England — presented a paper to a conference attending to the UK government's new monetary targeting policy. The paper argued, in its most-quoted formulation, that "any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes." The Bank of England was attempting to control inflation by targeting the growth rate of the money supply. Goodhart's observation was that the relationship between money supply growth and inflation — historically stable enough to serve as a policy target — would break down when it became the object of deliberate control, because financial institutions and economic actors would adjust their behaviour in ways that altered the relationship. The target would be hit; the underlying problem it was meant to address would not be solved.
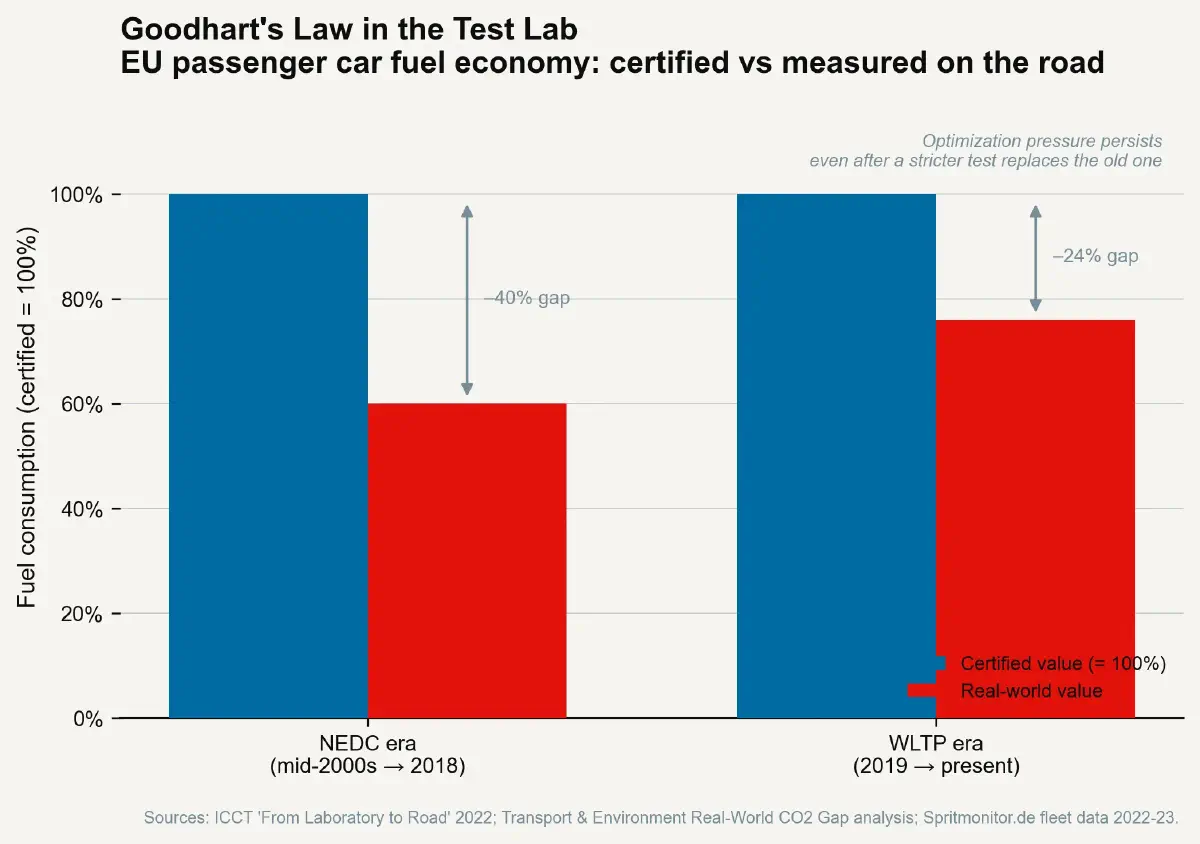
Goodhart's Law, as it became known, was a macroeconomic statement about monetary policy. It is also the most precise theoretical description available of the MPDI mechanism. The fuel economy test cycle is a statistical regularity — a measured correlation between test-cycle performance and real-world performance — that breaks down when manufacturers are placed under pressure to achieve a specific test result. The credit rating AAA category was a statistical regularity correlating with low default probability that broke down when structured finance products were engineered specifically to achieve it. The MPDI, in its general form, is a specific instance of Goodhart's Law applied to physical product measurement.
The Goodhart Trap in Practice#
Academic Research Metrics#
One of the most thoroughly examined contemporary instances of Goodhart's Law in operation is the transformation of academic research culture under bibliometric performance metrics. Beginning in the 1990s and accelerating through the 2000s, UK, Australian, Chinese, and various European university and national research funding systems adopted publication count, citation count, journal impact factor (JIF), and h-index as performance metrics for research quality assessment.
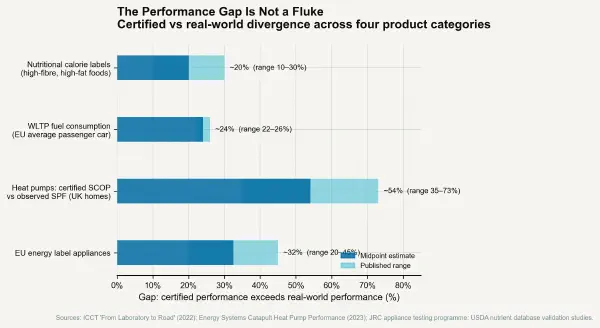
The MPDI for academic research metrics — measured as (bibliometric score performance ÷ actual research quality or impact − 1) × 100 — has been extensively documented. The publication count metric produced pressure to publish more papers at smaller units of incrementality, a practice known informally as least publishable unit salami-slicing. The journal impact factor metric — defined as the average number of citations to articles published in the journal in the preceding two years — produced gaming through citation cartels (journals encouraging mutual citation among affiliated authors), image-heavy review articles designed to accumulate citations without contributing original research, and editorial pressure to include controversial findings more likely to be cited (including, some evidence suggests, findings more likely to fail to replicate). The h-index metric produced self-citation strategies that, in some fields, now account for 10–30% of total citations to certain highly cited researchers.
None of these behaviours is unique to a few bad actors. They are the rational responses of researchers and institutions to an incentive system that rewards proxy performance (bibliometric scores) over underlying performance (scientific quality, reproducibility, real-world impact). The MPDI for academic research certification is a direct Goodhart consequence.
Hospital Performance Metrics in the UK NHS#
The UK National Health Service has operated various performance target regimes since the late 1990s. The most extensively analysed is the four-hour emergency department target — a requirement that 95% of patients presenting at NHS emergency departments be seen, treated, and either admitted or discharged within four hours. The target was introduced in 2000 to address waiting time problems. It produced measurable rapid improvement in documented waiting times — the measured performance metric improved substantially.
It also produced a substantial body of documented gaming behaviour: patients held in ambulances outside triage to avoid the clock starting; patients administratively discharged to a "corridor" for a brief interval then re-admitted to restart the clock in a different category; clinical decisions to discharge patients slightly faster than their clinical condition warranted to meet the threshold; and concentration of resources on the high-volume straightforward cases that most easily met the four-hour window at the expense of the low-volume complex cases that could not. The four-hour target is now an extensively studied case in the academic health policy literature on the costs of simplistic metric-driven management.
The MPDI for NHS emergency department four-hour performance — measured as (documented four-hour compliance rate ÷ true clinical quality of emergency care − 1) × 100 — is difficult to quantify precisely, because true clinical quality of emergency care is multi-dimensional and not directly observable. But the documented gaming behaviours demonstrate that the metric was being achieved at least partially through mechanism substitution: the measuring apparatus was being satisfied in ways that did not correspond to the improvement in patient care outcome the metric was intended to represent.
The Regulation Problem Campbell Identified#
Donald Campbell, an American social psychologist writing in 1979, proposed what became known as Campbell's Law: "The more any quantitative social indicator is used for social decision-making, the more subject it will be to corruption pressures and the more apt it will be to distort and corrupt the social processes it is intended to monitor." Campbell was writing about social science indicators — crime statistics, educational test scores, urban renewal metrics — but his formulation of the principle is precisely analogous to Goodhart's and applies with equal force to engineering certification metrics.
Campbell and Goodhart, working independently in different disciplines, identified the same structural property of measurement systems: the use of a measure for control purposes introduces an adversarial relationship between the measurer and the measured, in which the measured entity applies its information advantage about the relationship between the measure and the underlying variable to optimise for the measure rather than the variable. The MPDI is the quantitative expression of this optimisation in product certification.
The Three Conditions for Goodhart Collapse#
Not every measurement system collapses under optimisation pressure. The identification of conditions that prevent or slow the Goodhart collapse is the practical question for regulatory design.
The first condition that resists Goodhart collapse is when the measurement is the outcome — not a proxy for it. A race finish time is also the performance being certified; there is no gap between the measurement and the reality. In most product certification contexts, this condition is difficult to achieve because the "outcome" is defined over a population of use cases and time horizons that cannot be exhaustively tested, making proxy measurement unavoidable.
The second condition is when the regulator controls the test and the tested entity cannot observe the specific test conditions in advance. Surprise testing — where the regulator draws test conditions from a population of possibilities rather than using a fixed published protocol — defeats calibration for test conditions, because the test cannot be gamed if the test parameters are unknown. This is the principle behind the random drug testing programmes used in elite sport and the random workplace safety inspection programmes used in some regulatory jurisdictions. The MPDI for testing regimes with genuine unpredictability is substantially lower than for fixed-protocol testing, because the cost of optimising for all possible test conditions approaches the cost of optimising for the underlying performance itself.
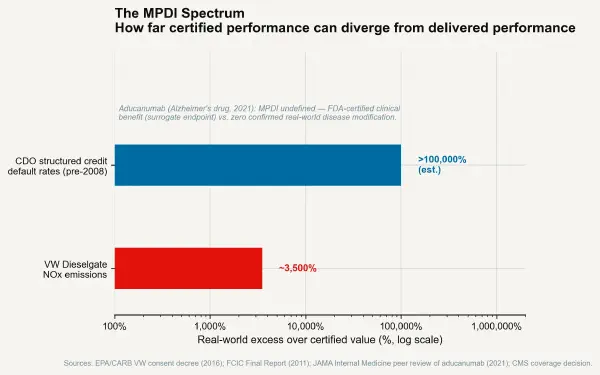
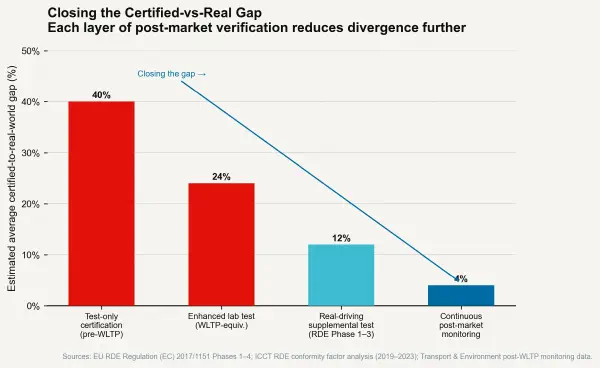
The third condition is post-market surveillance with consequence — ongoing monitoring of actual in-use performance after certification, with real regulatory consequences for MPDI above a defined threshold. The real-driving emissions (RDE) regulation that the EU implemented for automotive products in 2017 represents this approach: portable emissions measurement systems (PEMS) are attached to production vehicles operating in real traffic under real conditions, and emissions are assessed against conformity factors that allow limited divergence from type-approval results. The RDE programme has demonstrably reduced the road-transport MPDI for NOx in newer vehicles relative to the WLTP-only regime. It has not eliminated it — conformity factors still allow approximately 2.1× the type-approval limit in real-world driving — but the trajectory is toward lower MPDI.
The Goodhart Trap and AI Systems#
The most consequential ongoing Goodhart collapse may be in the domain of AI capability evaluation. Large-scale AI benchmarks — MMLU (Massive Multitask Language Understanding), HumanEval, GSM8K, BIG-bench — are published test sets designed to measure reasoning, coding, and mathematical capability in language models. They also serve as performance targets for commercial AI development programmes.
The MPDI for AI benchmark performance — measured as (benchmark score ÷ real-world reliability on analogous tasks − 1) × 100 — has been documented in multiple analyses. Models trained on data that overlaps with benchmark test sets show inflated benchmark performance relative to held-out evaluations. Models fine-tuned specifically for benchmark improvement show benchmark gains that do not generalise to similar out-of-distribution tasks. The benchmark, in Goodhart's terms, has become a target, and it is beginning to cease to be a good measure.
The next post examines what structural interventions are available to counteract the Goodhart dynamic — and what the regulatory contexts that have successfully maintained low MPDI have in common.