The Building That Needs a River#
In 2022, Microsoft disclosed that its global data centre infrastructure consumed approximately 6.4 million cubic metres of water — primarily for cooling — over the course of the year. Google's data centres consumed approximately 5.6 billion litres. Meta disclosed 3.9 billion litres. These figures appeared in sustainability reports framed around water stewardship commitments and replenishment pledges. What they described, stripped of the stewardship language, was the operational reality of the modern information economy: computation at scale requires evaporative cooling at industrial volumes, and the infrastructure that delivers the AI capabilities now embedded in hundreds of millions of daily workflows depends on a physical apparatus of water, chilled air, and power electronics whose scale, cost, and geographic constraints have no analogue in the digital metaphors used to describe the services they support.
The cloud is not a cloud. It is a building, and the building is hot. The question facing the AI era is whether the building can be cooled fast enough, cheaply enough, and in enough places to keep pace with the compute scaling thesis that is driving the largest wave of capital investment in the history of the technology industry.
The AI Scaling Thesis Has a Thermal Ceiling#
Every additional trillion-parameter model, every additional training run at the frontier of capability, every additional inference request served to hundreds of millions of users requires heat to be extracted from silicon at rates that are pushing past the limits of conventional facility design. The data centre industry is not a passive substrate for the AI revolution — it is an active constraint on its shape. Understanding that constraint begins with the arithmetic of what AI actually costs to cool.
The binding variable is not capital expenditure on chips. It is the ratio of useful computation to the total energy input required to perform it — and the share of that total energy that flows to the cooling system rather than to the computation itself.
Inside the Thermal Budget of an AI Facility#
Power Usage Effectiveness and Its Declining Returns#
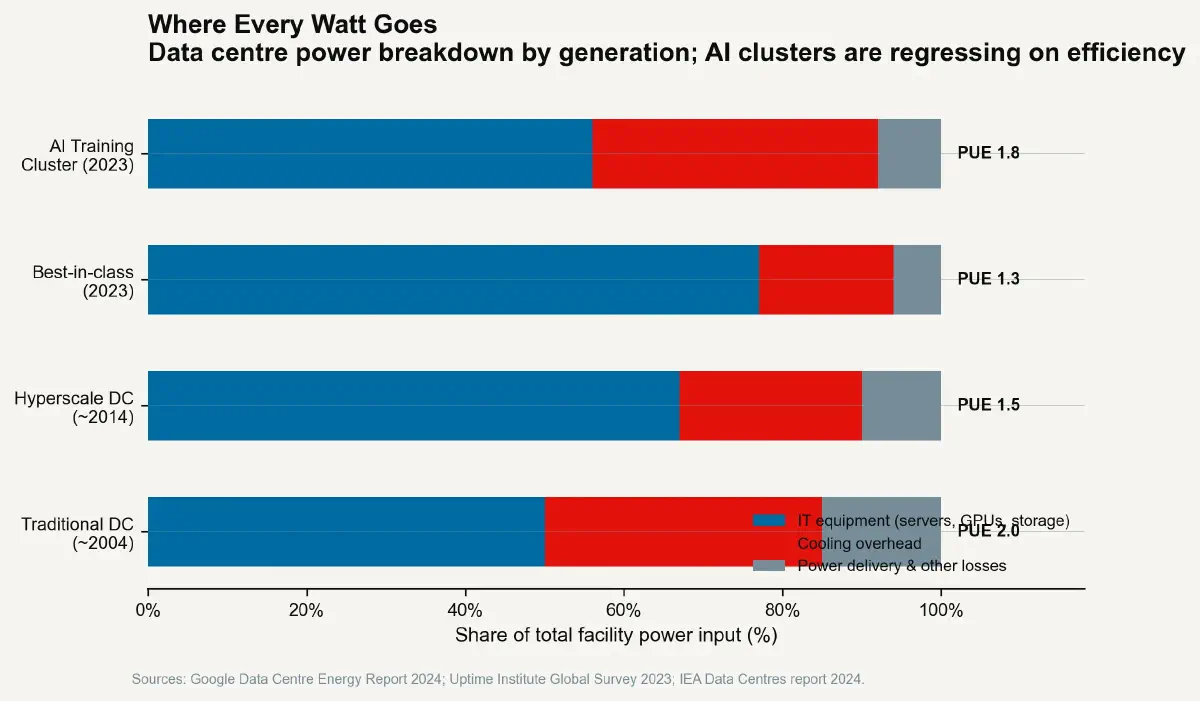
The industry's standard metric for data centre energy efficiency is Power Usage Effectiveness (PUE): the ratio of total facility energy consumption to the energy consumed by the IT equipment itself. A PUE of 1.0 would mean all facility energy goes to computation — a thermodynamic impossibility, since all computation becomes heat and all that heat must be removed. A PUE of 1.5 means 50% overhead energy is consumed by cooling, lighting, power conversion, and other facility systems for every unit of compute energy. A PUE of 2.0 means the cooling infrastructure consumes as much energy as the servers.
Google's fleet average PUE as of 2023 was approximately 1.10 — achieved through economies of scale, custom hardware, and optimised free-air cooling in temperate climates. Microsoft's data centre fleet averaged approximately 1.18. These figures represent the current frontier of large-scale facility design. They also represent air-cooled or hybrid-cooled facilities running workloads that, while dense by historical standards, were designed to be manageable within air-cooling limits.
The AI training rack changes this arithmetic. A rack of NVIDIA H100s running at full GPU utilisation draws approximately 10–12 kilowatts. A rack of NVIDIA GB200 NVL72 systems draws approximately 120 kilowatts. The transition to AI-optimised hardware has increased rack-level power density by a factor of 10–12 in roughly three years. Air cooling — even the most aggressive chilled-air systems with raised floor plenum pressures and perforated tile configurations — cannot extract heat from a 120 kW rack without reaching surface temperatures that would reduce GPU life and trigger thermal throttling. Liquid cooling is not optional for these systems. It is a technical prerequisite.
Liquid cooling adds capital expenditure, operational complexity, and — crucially — a new class of supply-chain dependency. Each liquid-cooled rack requires direct plumbing connections, coolant distribution units with pumps and heat exchangers, and facility-level chilled water infrastructure. The capital cost of this infrastructure — in a purpose-built liquid-cooled AI training facility — runs to approximately $3–5 million per megawatt of IT load, comparable to or exceeding the cost of the compute hardware itself. The PUE for a liquid-cooled AI training facility, depending on climate and configuration, runs approximately 1.03–1.10 for the cooling system alone — a figure that looks excellent in percentage terms but represents an absolute energy overhead that, at hyperscale, is measured in hundreds of megawatts.
The Geography of Heat Removal#
The thermal constraint is not only economic — it is geographic. The most energy-efficient data centre cooling strategy exploits low ambient temperatures to enable economiser modes, where outside air or cooled groundwater provides chilling without mechanical refrigeration. This is why major data centre clusters are concentrated in Iceland, Finland, Ireland, Oregon, and the Columbia River Gorge: geography provides free cooling.
AI training demands are beginning to strain these geographic concentrations. The Columbia River Gorge, long a preferred location for hyperscale facilities due to its temperate climate, low-cost hydroelectric power, and water availability, is facing regulatory pressure on water withdrawal permits for new evaporative cooling towers. Multnomah County, Oregon, imposed a moratorium on new data centre construction in unincorporated areas in 2021. Dublin, Ireland — another major European data centre hub — saw grid operator EirGrid warn in 2022 that data centres were consuming 18% of national electricity supply, with projections reaching 30% by 2030, leading to connection restrictions for new facilities.
The heat load of AI is not abstractly large — it is concretely sited. Each training cluster requires power infrastructure, cooling infrastructure, and a geographic location where both can be provided at the required scale. The concentration of these requirements at a small number of globally suitable sites is making the location of AI infrastructure a strategic constraint as significant as the chip supply chain.
The Economics of the Cold Plate#
The transition to liquid cooling is not only a thermal engineering story — it is a supply chain and maintenance story with significant operational implications. A conventional air-cooled server can be managed by any competent data centre operations team, replaced with commodity parts from standard distribution channels, and repaired in place with standard tooling. A liquid-cooled AI server requires coolant distribution units with pump reliability contracts, non-conductive coolant chemistry management, leak detection systems, and drain-and-fill procedures that add time and complexity to every hardware replacement cycle.
The total cost of ownership for an AI training cluster — when cooling infrastructure amortisation, coolant management, additional facilities engineering staff, and the energy premium of liquid cooling infrastructure is included — exceeds the cost of the compute hardware itself over a 5-year deployment cycle at current scale. The capital-to-operating cost ratio of AI infrastructure is fundamentally different from the general-purpose cloud computing model that preceded it, where commodity hardware, standardised air cooling, and high turnover drove costs toward commodity economics. AI training is, in thermal terms, closer to an industrial chemical process facility than a consumer internet server farm — with analogous infrastructure requirements and analogous management overhead.
AI's Energy Budget and the Question Nobody Is Answering Publicly#
The electricity demand implications of AI data centre scaling are now actively discussed in terms of grid capacity and renewable energy procurement. The thermal implications — the water, the cooling tower discharge, the waste heat streams — receive less attention. A 100 MW AI training facility operating at a PUE of 1.15 rejects approximately 15 MW of heat to the environment continuously, requiring either evaporative cooling (which consumes water) or dry cooling (which requires more land and reduces efficiency in warm climates) or heat recovery (which requires an industrial heat consumer within economic piping distance).
The TDR inflection for AI data centres — the point at which the infrastructure cost per watt dissipated begins rising faster than compute density — was crossed roughly at the transition from air to liquid cooling around 2022–2023. Above approximately 30–40 kW per rack, air cooling is no longer economically viable for continuous operations. Above approximately 70–80 kW per rack, even standard liquid cooling approaches are reaching their practical limits, and immersion cooling — submerging servers in dielectric fluid baths — is being piloted by Google, Microsoft, and Intel as the next generation of high-density thermal management.
Immersion cooling can handle heat fluxes above 200 W/cm² and enables rack densities exceeding 200 kW, but it introduces a new set of operational constraints: hardware insertion and removal require draining or displacing fluid, standard server component form factors are incompatible with immersion baths, and the dielectric fluids themselves carry supply chain, environmental, and materials cost considerations. The cooling solution for the generation of AI hardware following the current GPU clusters has not yet been industrialised.
The Constraint That Scales Faster Than the Capability#
The data centre arithmetic of AI reveals an asymmetry that no benchmark measures. The capabilities of AI systems scale at the pace of chip development, algorithm refinement, and training compute investment — and across these dimensions, the pace has been rapid. The cooling infrastructure required to support that compute scaling grows at a pace determined by construction timelines, grid interconnection queues, water permit processes, and the engineering lead times of industrial cooling systems. These timelines are measured in years; chip development cycles are measured in months.
The result is a growing gap between the computational ambition of the AI industry and the physical infrastructure required to realise it. Data centre operators are not passive infrastructure providers watching AI scale past them — they are building. But the thermal constraint is a physical variable that cannot be accelerated by additional investment beyond what physics and geography allow. The binding constraint on AI's next scaling step is not a chip. It is a cooling tower. The next post shifts from the data centre to the automobile and examines a different thermal window — the narrow temperature band within which a lithium-ion battery can perform, age, and survive.