The Room That Could Not Get Cold Enough#
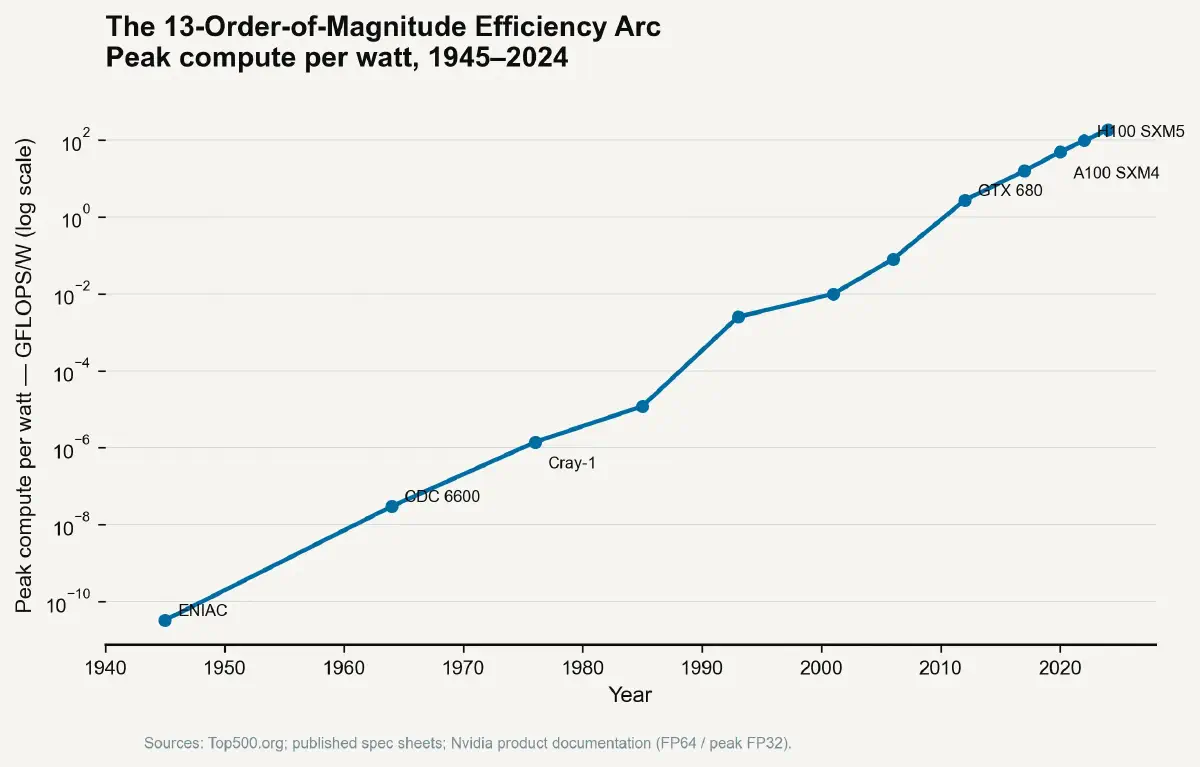
In 1945, the ENIAC computer occupied 167 square metres of the University of Pennsylvania's Moore School of Electrical Engineering, consumed 150 kilowatts of power, and generated enough heat to warm a small house in January. Its 17,468 vacuum tubes were, by the standards of the day, a triumph of miniaturisation compared to relay-based predecessors. They were also, by the standards of two decades later, a thermal catastrophe. Each tube functioned by heating a filament to incandescence, boiling off electrons into a vacuum — an act that converted perhaps 1% of its electrical input into signal and 99% into heat. The engineers who maintained ENIAC were less technicians than firefighters, replacing failed tubes at a rate of roughly one every two days and managing the ambient temperature of the room as a primary engineering variable.
The vacuum tube did not die because something cleverer came along, though the transistor was indeed cleverer. It died because its fundamental operating principle was thermally incompatible with further miniaturisation. Physics made the decision that engineers were debating. And the same physics that killed the vacuum tube is, seventy years later, stalking the silicon transistor.
Heat Is Not a Side Effect — It Is the Primary Variable#
The conventional history of the semiconductor revolution is told as a story of shrinking geometry: transistors getting smaller, more of them fitting per square millimetre, processing power multiplying accordingly. This account is accurate in its outline and misleading in its emphasis. Every step on the shrinkage curve required not only a new lithographic technique but a new thermal solution. The transistor did not replace the vacuum tube because it was smaller. It replaced the vacuum tube because it was cold.
The real governor of the computing revolution — from 1947 transistors to 2nm nodes — has been the Thermal Density Ratio: the relationship between the heat flux a device generates per unit area and the infrastructure cost required to extract that heat per watt dissipated. When cooling innovation drove TDR downward, Moore's Law ran. When TDR stopped falling, the Law hit its wall.
The Architecture of Thermal Failure#
Why Electrons Always Become Heat#
The physical link between computation and heat is not an engineering accident — it is a consequence of the second law of thermodynamics. Every transistor switching event — from logic-0 to logic-1 or back — dissipates energy as heat. Landauer's principle, articulated by physicist Rolf Landauer in 1961, establishes that erasing one bit of information in a system at temperature T requires dissipating a minimum energy of kT·ln(2), where k is Boltzmann's constant. At room temperature, this theoretical minimum is approximately 0.018 electron-volts per bit erasure — vanishingly small, orders of magnitude below what current transistors actually dissipate. But it establishes that heat generation is not a flaw in transistor design. It is the price of irreversible computation, baked into physics.
In practice, the MOSFET transistors in modern chips dissipate energy not primarily through Landauer-minimum erasure but through two dominant mechanisms: dynamic power (the capacitive switching energy required to charge and discharge the transistor gate with each logic transition, proportional to CV²f, where C is gate capacitance, V is supply voltage, and f is clock frequency) and static leakage (the current that flows through the transistor even when it is nominally off, which has become the dominant power drain at nanometre scales as gate oxide thickness approaches a few atoms). Both mechanisms convert electrical energy to thermal energy. Both scale with transistor density in ways that have driven the industry's thermal engineering agenda for fifty years.
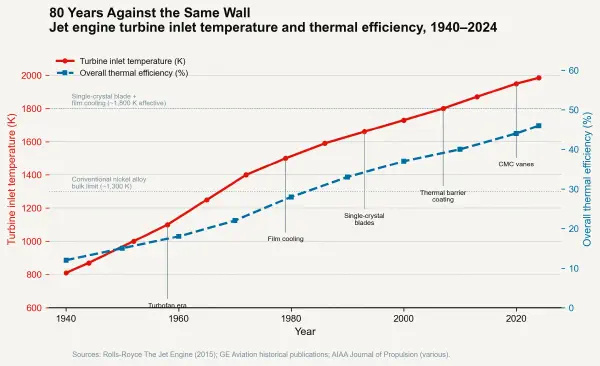
Gordon Moore's 1965 observation — that the number of components per integrated circuit was doubling approximately every year — was initially interpreted as a manufacturing density forecast. Robert Dennard's 1974 scaling theory provided the physical rationale: as transistors shrank by a linear factor k, their power density remained approximately constant, because reduced supply voltage compensated for increased transistor count. This Dennard scaling is why clock speeds and performance could rise together without proportional power increases through the 1990s.
Dennard scaling broke down around 2004–2005. Below approximately 90 nanometres, gate oxide leakage became severe enough that voltage could no longer be scaled down proportionally with feature size. Power density began rising with each process generation. Intel's Pentium 4 "Prescott" core, released in 2004 at 90nm, consumed approximately 115 watts — enough that Intel's thermal engineers recommended a minimum heatsink mass of 550 grams and airflow rates that bordered on industrial. Clock speeds plateaued. The industry pivoted to multicore architectures, distributing computation across multiple lower-clocked processors — a thermal coping strategy dressed as a performance strategy.
The Hierarchy of Heat Solutions#
The history of thermal management in computing is a nested series of engineering responses, each adequate for approximately one or two process generations before the next density doubling required a step change rather than an increment.
The first generation — passive heatsinks — relied on conduction through a metal block into natural convection from fin surfaces. IBM's first mainframe transistor modules in the 1960s used aluminium heatsinks with pin-fin arrays, adequate for power densities below approximately 1 W/cm². The second generation introduced forced-air cooling: fans drove air over progressively more elaborate fin geometries, extending the viable range to approximately 5–10 W/cm² through the personal computer era of the 1980s and 1990s. The Pentium era of the early 2000s pushed into the 20–30 W/cm² range, exhausting air-cooling's practical ceiling for desktop-class processors and driving the first serious adoption of liquid cooling in consumer electronics.
Liquid cooling — direct-to-chip cold plates circulating chilled water or dielectric fluid — extended the viable range to approximately 50–80 W/cm² for high-performance workstations and server processors. It also introduced the infrastructure dependency that now defines the economics of the computing industry: a chip that cannot be air-cooled cannot be deployed without specialised facility infrastructure, and the cost of that infrastructure is substantial, continuous, and growing.
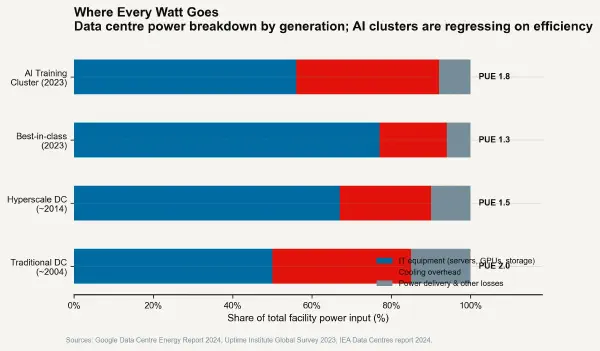
The modern GPU, in its highest-performance AI training configuration, generates approximately 700 watts in a package the size of a large paperback book — a heat flux approaching 100 W/cm² at the die surface. This figure sits in the thermal range of nuclear reactor fuel rod surface flux and exceeds the surface heat flux of the sun's photosphere by a factor of approximately two. Extracting this heat without destroying the silicon requires water-cooling channels machined to sub-millimetre tolerances, microchannel heat exchangers with surface areas measured in square metres compressed into cubic centimetres, and facility-level chilled water infrastructure whose capital cost is, in modern hyperscale AI data centres, comparable to the capital cost of the compute hardware itself.
The Inflection Point That the Roadmap Missed#
The semiconductor industry's official technology roadmap — the International Technology Roadmap for Semiconductors (ITRS), succeeded by the Industry Roadmap for Devices and Systems (IRDS) — has tracked transistor density, feature size, and power consumption projections for decades. Its thermal projections have historically been interpolated from expected performance improvements without independent validation of whether the required cooling infrastructure would exist.
The divergence between roadmap assumptions and physical reality became acute around 2015–2016. The roadmap's "More Moore" trajectory projected continued performance scaling through 7nm and 5nm nodes. Chipmakers achieved those nodes — transistor counts per die did increase — but power scaling did not follow the expected curve. TSMC's 5nm N5 process, used in Apple's M1 and A14 chips, delivered approximately 15% better performance per watt than 7nm N7. TSMC's 3nm N3, released in 2022, delivered approximately 10–15% additional performance per watt improvement. The curve is flattening. Each successive node delivers fewer thermal dividends.
The AI scaling hypothesis — the thesis that larger neural network models continue to improve capability roughly exponentially with additional training compute — has been the primary demand driver for next-generation chip platforms since approximately 2020. The computation required to train GPT-4-class models is estimated at approximately 10²³–10²⁴ floating-point operations. The computation required for successors in the scaling hypothesis will be multiples higher. Each step up the scaling curve increases the thermal load of the training cluster. NVIDIA's GB200 NVL72 rack system, designed for large-scale AI training, draws approximately 120 kilowatts per rack and requires liquid cooling infrastructure capable of extracting approximately 95% of that as heat. Deploying these systems at hyperscale requires utility-grade power and cooling infrastructure.
The Real Governor Has Always Been the Radiator#
The history of the transistor describes a 75-year race between what computation requires and what cooling can provide. For most of that period, cooling ran slightly faster: each generation's thermal challenge was solved in time for the next generation's density to be commercially viable. Starting in approximately 2005, the race became a pursuit — performance scaling slowed to match what cooling could support rather than driving cooling to keep up.
The critical recognition is that the limit on AI model scale today is not lithography resolution, chip cost, or algorithm design. In the short term, it is the availability of liquid-cooled data centre space connected to adequate power infrastructure. The thermal constraint that killed the vacuum tube, that plateaued single-core clock speeds, and that is now slowing the transistor density curve is the same thermodynamic reality at every scale. Computation generates heat. Removing heat costs money, space, energy, and water. The history of computing is the history of making that removal cheap enough to stay ahead of what computation demands — and the present is the era in which that solution is becoming the dominant cost.
The next post moves from the chip to the building and examines the data centre arithmetic of the AI era: where cooling costs are going, what liquid cooling infrastructure actually requires, and why the hyperscale operators who are building the AI economy are spending as much engineering effort on chilled water circuits as on GPU specifications.