The Man Who Refused to Write a Monolith#
In August 1991, Linus Torvalds — a 21-year-old computer science student at the University of Helsinki — posted a message to the Usenet newsgroup comp.os.minix. The message began: "I'm doing a (free) operating system (just a hobby, won't be big and professional like gnu) for 386(486) AT clones." It concluded with an invitation to feedback on the design of the project, which Torvalds had named Linux.
Andrew Tanenbaum, a professor at the Vrije Universiteit Amsterdam and the author of Minix — the operating system Torvalds had been modifying — responded with a post that has become one of the most quoted academic disputes in software engineering history. Tanenbaum's argument was that Torvalds's design choice — a monolithic kernel, in which a large body of operating system code runs in a single privileged address space — was obsolete. Modern operating system design, Tanenbaum argued, uses a microkernel architecture, in which only a minimal core runs in privileged mode and all other OS services run in user space, communicating through well-defined message-passing interfaces. The monolithic kernel, Tanenbaum wrote, would not scale.
Tanenbaum was theoretically correct and practically wrong. Linux, still using a fundamentally monolithic kernel architecture, now runs on approximately 96% of the world's supercomputers, the majority of server infrastructure globally, and effectively all Android devices. Tanenbaum's MINIX microkernel design never achieved comparable deployment. The Linux monolith scaled, not because monolithic design was architecturally superior to microkernel design — Tanenbaum's theoretical arguments for microkernel modularity remain valid — but because Linux's culture of code review, interface discipline, and the practical constraint of a flat contributor hierarchy produced a different kind of modularity than formal architecture could deliver.
How Modularity Prevents CRIP Crossing#
The Interface Discipline of TCP/IP#
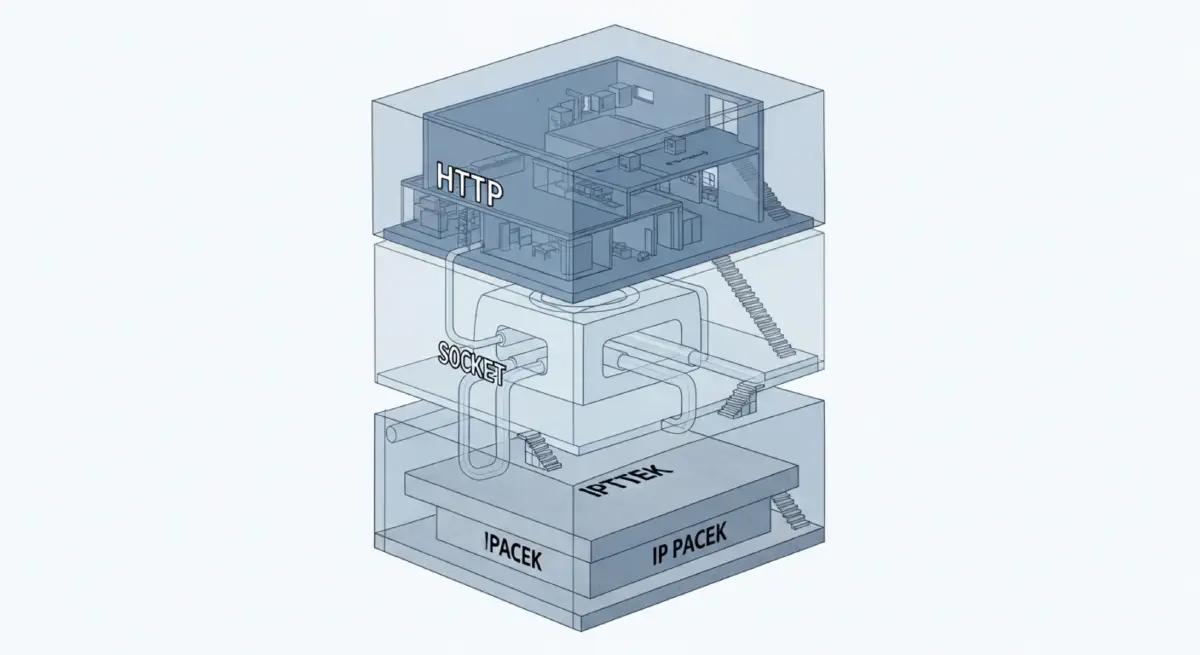
The Internet Protocol suite's foundational design principle, articulated in RFC 760 (the original IP specification, 1980) and in subsequent RFC commentaries by Jon Postel, can be summarised as the principle of least functionality at the network layer: "routers should do as little as possible; push intelligence to the endpoints." The IP protocol specifies how packets are addressed and forwarded; it does not specify what those packets contain, what applications are running, or what transport behaviour is expected. TCP (Transmission Control Protocol) handles reliability and ordering above the IP layer, as an optional additional service. Application protocols (HTTP, SMTP, FTP) operate above TCP, as optional additional services.
This layered architecture, where each protocol layer has a strictly bounded scope and communicates with adjacent layers only through defined interfaces, is a deliberate CRIP management structure. The complexity of the internet — now connecting billions of devices running millions of applications — is distributed across layers that are individually manageable:
- The IP forwarding layer is simple enough that its behaviour can be expressed in a few hundred lines of code, and its interactions with the layers above and below it are defined by documented interface specifications.
- The TCP reliability layer is more complex, but its complexity is bounded: it knows nothing about the application content it carries, and its interaction with IP below it is defined by the IP datagram interface.
- The application layer is arbitrarily complex — HTTP/3 (QUIC) is a highly complex protocol — but its failures affect only the applications running it; they cannot propagate down to the IP forwarding layer or affect other unrelated applications.
The CRIP for the internet's core routing infrastructure is extremely high, because the architecture has been designed so that each additional application, each additional protocol, and each additional connected device adds its complexity only to the layer where it exists, not to the full system. The IPv4 routing table — which must be maintained by every core internet router — has grown to approximately 900,000 routes as of 2023. This is a large number, but it is manageable because the routing table is a flat list of prefix-forwarding decisions, not a complex interaction graph.
The comparison with a hypothetical internet designed differently — one where routers were responsible for application-level decisions, where every new application required changes to core routing infrastructure — illustrates why CRIP management was built into TCP/IP at its inception. Jon Postel and Vint Cerf, the principal architects, were building a system intended to work "even if most of the intermediate nodes do not exist or are unreliable." This design requirement drove architectural choices that incidentally produced excellent CRIP management properties.
Git's Complexity Architecture#
Linus Torvalds created Git in 2005 in approximately 10 days, after the BitKeeper version control system the Linux kernel project had been using became commercially unavailable. The design constraints Torvalds applied to Git were explicitly derived from his experience managing the complexity of the Linux kernel development process: the system had to handle large numbers of developers making concurrent changes to a shared codebase, had to maintain a complete history of changes with cryptographic integrity, and had to work in the absence of a central server.
The resulting architecture is a directed acyclic graph of content-addressed objects — commits, trees, blobs — where each object's identity is a SHA-1 hash of its content. This design produces a remarkable CRIP property: each commit is computationally independent of every other commit. The full history of the repository is derivable from the current commit graph without any external state. Concurrent commits on separate branches cannot produce inconsistencies in the underlying object store — they produce a branched graph that must be explicitly merged when integration is desired.
The CRIP management of Git's design is in the simplicity of its core data model. Adding a feature to Git — a new command, a new protocol, a new file format — cannot change the behaviour of the core object store because the core object store's behaviour is defined only by its content-addressing mathematics, not by any mutable state. The failure modes of git cherry-pick are bounded to the cherry-pick command and do not propagate into git log. This is architectural CRIP bound by design, not by discipline.
The Linux Kernel's Practical CRIP Management#
Linux does not comply with the theoretical microkernel ideal, but it has developed institutional CRIP-management practices that achieve practical reliability at scale. The kernel has maintained a rule, enforced socially through the maintainer hierarchy, that no module is merged without code review by at least one subsystem maintainer and typically two. The Linux kernel development model — decentralised development, pull requests to subsystem maintainers, subsystem maintainers' pull requests to Torvalds — creates a hierarchical review structure where CRIP-crossing changes (changes that introduce interactions with multiple subsystems whose combined behaviour has not been adequately analysed) tend to be identified and blocked in the review process before merge.
The Linux kernel has approximately 33 million lines of code as of 2023 and is maintained by approximately 4,000 active developers. It runs on approximately 3 billion devices. Its CRIP management is not architectural in the formal sense — the kernel contains many known architectural infelicities and accumulated complexity in its older subsystems. Its CRIP management is institutional: a culture of code review, maintainer accountability, and explicit interface documentation that has maintained functional reliability at scale despite code volume that would seem to predict catastrophic complexity failure.
The CRIP Advantage of Deliberate Smallness#
The networking and operating system examples illustrate that CRIP management is achievable through architectural design and institutional culture. In both cases, the systems that have remained reliably functional at large scale share a property: someone, at a critical point in their design history, made an explicit decision to keep the core system small and to push complexity to peripheral layers where it could be bounded.
Jon Postel's "end-to-end" principle for TCP/IP, Torvalds's flat object model for Git, the C standard library's minimalism relative to later runtime environments — these are not accidental properties. They are the survivable structures from a selection process in which more complex alternatives either failed or never achieved comparable deployment because their complexity prevented the reliability required for adoption.
The lesson for organisations building complex systems is not that simplicity is always achievable — it is that architectural decisions made early in a system's lifetime determine whether CRIP can be managed as the system grows. A system designed with bounded interfaces, hierarchical complexity management, and a culture of explicit scope enforcement can sustain growth to large complexity while remaining below operational CRIP. A system designed for maximum early functionality — with complex interdependencies, shared mutable state, and no explicit interface discipline — will cross CRIP early and produce CRIP-crossing failure modes as it grows. The next post examines what happens to a domain that grew complex without that prior discipline: hospital clinical protocol systems.